1.数据错误:
错误类型
脏数据或错误数据
比如, Age = -2003
数据不正确
0 代表真实的0,还是代表缺失
数据不一致
比如收入单位是万元,利润单位是元,或者一个单位是
美元,一个是人民币
数据重复
2.缺失值处理:
处理原则
缺失值少于20%
连续变量使用均值或中位数填补
分类变量不需要填补,单算一类即可,或者用众数填补
缺失值在20%-80%
填补方法同上
另外每个有缺失值的变量生成一个指示哑变量,参与后续的建模
缺失值在大于80%
每个有缺失值的变量生成一个指示哑变量,参与后续的建模,原始变量不使用。
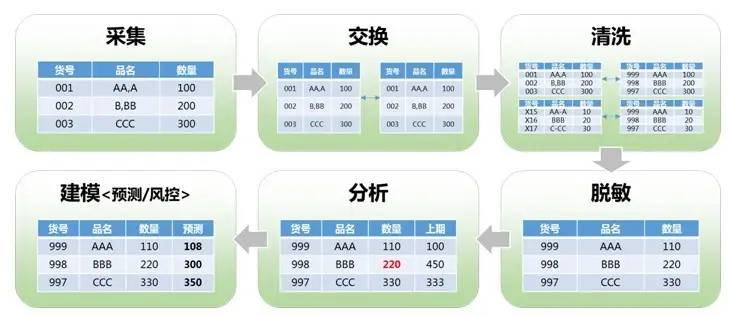
3.离群值
3.1单变量离群值处理:
.绘图。
在图中找出离群的异常值,根据情况对其进行删除或者对数据进行变换从而在数值上使其不离群或者不明显。
学生化(标准化)
用变量除以他们的标准误就可得到学生化数值
建议的临界值:
SR >2 ,用于观察值较少的数据集
SR >3,用于观察值较多的数据集
3.2多变量离群值
1.绘图。
在图中找出明显的离群值
2.聚类法确定离群值(不要对原有数据进行改变)
聚类效果评判指标:(群内方差(距离)最小化,群间方差(距离)最大化;这里方差可以理解为一种距离(欧式距离的平方欧式距离))
了解清洗后,接下来,就来学习一下Python的数据清洗吧!
现在有一份心脏病患者的数据,经过问卷调查之后,最终录入数据如下:
- Age:年龄
- Areas:来自哪里,有A/B/C/D四个地区
- ID:患者的唯一识别编号
- Package:每天抽几包烟,缺失的为-9,代表不抽烟
- SHabit:睡眠习惯,1-早睡早起;2-晚睡早起;3-早睡晚起;4-晚睡晚起
为了学习方便,假设这里就这些变量吧。
看完这个变量说明我不淡定了,这个数据存在很多问题啊!Age是年龄?158是什么鬼??还有6岁小孩,每天抽1包烟?ID是唯一编号吗?为什么有3个1号、2个5号、2个9号、2个10号?
这个数据问题太多了,因此我要逐一来清洗一下,顺便学一下数据清洗方面的知识。
1. 删除重复
3个1号、2个5号、2个9号、2个10号。这是数据录入中经常出现的问题重复录入了,所以首先我要把那么多占空间又没用的重复数据剔除。
介绍两个方法:data.duplicated() 和 data.drop_duplicates(),前者标记出哪些是重复的(true),后者直接将重复删除。
所以drop.duplicates直接就将重复值删除了,默认保留第一条。
以上是按照有两行数据,这两行数据的所有变量值都一样,这么这两行就算重复数据,但有时候我们会只根据一个变量来剔除重复,比如值根据Areas这个变量,那么A/B/C/D四个地区只会保留第一条,传入take_last=True则保留最后一个:
A/B/C/D每个地区值保留一条数据了。
2. 异常值检测
在第一步剔除重复值之后。得到了无重复数据的data_noDup:
第二步,我想检测一下数据中有没有异常值。首先可以用 describe() 进行一个描述分析,在第五天的学习中(第5天:Pandas,露两手)已经学过如何对数据进行描述:
有两个变量值得我们注意,一个是age,最大值158、最小值6,肯定有问题,另一个是package,最小值是-9,存在缺失。
用 data[条件] 的方式可以看一下有多少age大于100、age小于10,、package为-9的:
好了,检测完毕,现在来处理这些异常值。
3. 替换
我要把异常的年龄替换成缺失,把package等于-9的替换成0(换成0是因为,不抽烟其实也就是抽烟数量为0,这样还能少一些缺失值)。
替换的方式有2种,字典,或者替换关系组成的数组:
(1)data.replace([A, B], [A_R, B_R]),如果这里替换之后的值A_R和B_R是一样的,那么[A_R,B_R]直接是A_R就可以了
(2)data.replace({A:A_R, B:B_R}),这是字典的方式。
所以,这里想要将age的6、158替换成缺失,就应该为:
data_noDup[Age].replace([158, 6], np.nan)
将package的-9替换成0:
data_noDup[Package].replace(-9, 0)
替换之后的数据命名为data_noDup_rep:
4. 数据映射
接下来的一些处理,是为了变量能够更加便于分析,首先是要进行数据映射。什么是映射呢?以Areas为例,Areas取四个地区:A/B/C/D, 这四个地区在分析的时候并没有什么意义,但A/B/C为城市,D为农村,这个很有意义,所以我要根据areas创建新变量CType:U-城市、R-农 村,映射关系如下:
方法就是写一个映射字典,把A/B/C变成U,把D变成R:
areas_to_ctype={A:U,B:U,C:U,D:R}
然后使用 map(映射字典) 去创建新变量CType:
data_noDup_rep[CType]=data[Areas].map(areas_to_ctype)
其实用替换也可以,但是替换是在原列上替换,而映射自己可以新建一个变量。
5. 数值变量类型化
接下来还要处理的变量是年龄Age,需要分成四组,
- 0:30岁以下,也就是0到30岁
- 1:30-40岁
- 2:40-50岁
- 3:50岁以上,不妨设为50-100岁
这个问题如果用映射MAP的话就麻烦了,每一个年龄都要写一个映射。使用 cut 函数来分割,就可以自己分割成几个组。
1)首先要设置几个分割点:0、30、40、50、100:cutPoint=[0,30, 40, 50,80]
2)接着,用 cut(data, cutPoint) 的格式对age按照cutPoint进行划分:pd.cut(data_noDup_rep[Age],cutPoint)
3)最后,将这个赋给新变量ageGroup:data_noDup_rep[ageGroup] =pd.cut(data_noDup_rep[Age],cutPoint)
这样很不好看有木有?怎么把四个组分别用0、1、2、3来表示呢?
设定一个组标签groupLabel=[0,1,2,3],指定 labels=groupLable 即可。
data_noDup_rep[ageGroup] =pd.cut(data_noDup_rep[Age],cutPoint, labels=groupLabel)
一个问题来了,依稀记得之前做过一个项目,样本量有7000,年龄分组是按照分位数来分的,那再python中能否实现?
可以的,用 qcut(data, n) 就可以,按照分位数分n组,比如分2组,那么就按照中位数来分,分4组,就按照四分位数来分。对这个例子我分两组:
data_noDup_rep[ageGroup] =pd.qcut(data_noDup_rep[Age],2)
6. 创建哑变量
哑变量一般用于两种情况:一是变量值是无序并列的,比如例子中的SHabit,四个选项1、2、3、4是并列的;另一种就是多选题,也需要生成哑变量。
以本例中的SHabit(睡眠情况)为例,四个取值是并列的,没有顺序,因此我们要把这1个问题变成4个:
SHabit(睡眠习惯,1-早睡早起;2-晚睡早起;3-早睡晚起;4-晚睡晚起)
变成:
SHabit_1:是否早睡早起?(0-否,1-是)
SHabit_2:是否晚睡早起?(0-否,1-是)
SHabit_3:是否早睡晚起?(0-否,1-是)
SHabit_4:是否晚睡晚起?(0-否,1-是)
使用 get.dummies( data[SHabit] ) 就可以直接搞定:
生成了四个变量。要把它合并入原数据data_noDup_rep中去,只要用 merge 就可以了(上一文刚刚介绍过数据的合并,戳复习→第6天:数据合并)
data_noDup_rep_dum =pd.merge(data_noDup_rep, pd.get_dummies(data_noDup_rep[SHabit]),right_index=True, left_index=True)
(注:因为合并键值是索引,因此要用right_index=True和left_index=True)
一个问题:变量名1、2、3、4太丑了!
可以在get_dummies函数中加 prefix= 选项为名字加一个前缀:
data_noDup_rep_dum =pd.merge(data_noDup_rep, pd.get_dummies(data_noDup_rep[SHabit], prefix=SHabit ), right_index=True, left_index=True)



















